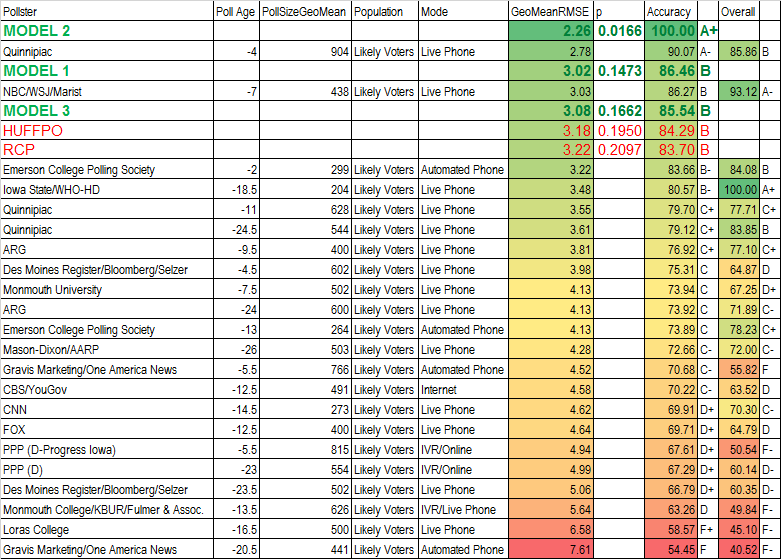
Welcome back! We didn't provide any predictions for the recent Nevada Republican caucus, because there were too few polls on which to base our models. So on we go to the upcoming South Carolina Democrat primary. Both our models forecast blowout victories for Clinton, compared with the poll averages, because of last minute movement towards Clinton. Here are the numbers:
Model 1 - Clinton 75.2%, Sanders 24.8%
Model 2 - Clinton 69.8%, Sanders 30.2%
We thought it would be interesting to provide the probability of each of the remaining 7 presidential candidates achieving the nomination of his or her party. We based a simple model on two criteria: 1) how many delegates has each candidate accumulated so far as a fraction of the total needed to secure a majority; and 2) the current standing in the national polls. Here is the result.
Model 1 - Clinton 75.2%, Sanders 24.8%
Model 2 - Clinton 69.8%, Sanders 30.2%
We thought it would be interesting to provide the probability of each of the remaining 7 presidential candidates achieving the nomination of his or her party. We based a simple model on two criteria: 1) how many delegates has each candidate accumulated so far as a fraction of the total needed to secure a majority; and 2) the current standing in the national polls. Here is the result.

Clinton has the highest probability of achieving her party's nomination. However, her direct competitor Sanders is only about 5 points behind. Trump's probability of winning is a bit lower, but in a much larger field; his probability of winning is more than the second place and third place combined. Of course these numbers will be updated after delegates are awarded in the SC primary. After that, Super Tuesday is make or break for Kasich and Carson.


































 RSS Feed
RSS Feed